Meine Erfahrung im Posteditieren maschineller Übersetzungen im Sprachenpaar Deutsch-Spanisch
Zweieinhalb Jahre lang war ich als technischer Übersetzer aus dem Deutschen ins Spanische in einem IT-Unternehmen tätig. Im Team der sogenannten internationalen Redakteure sorgte ich für die korrekte Übersetzung und kulturelle Anpassung der deutschsprachigen Texte für den spanischen und mexikanischen Markt. Meine Kollegen taten das Gleiche für ihre jeweiligen internationalen Märkte. In dieser Zeit arbeiteten wir mit dem Angebot des Anbieters maschineller Übersetzungen (MÜ) DeepL, was manchmal hilfreich war, beizeiten aber auch sehr amüsante und häufig haarsträubende Ergebnisse lieferte.
Die nachfolgenden Zeilen sind kein wissenschaftlich fundierter Aufsatz, es folgt mein persönlicher Erfahrungsbericht zum Einsatz von DeepL in der Anfertigung und dem Post-Editing technischer Übersetzungen aus dem Deutschen ins Spanische. Zu Beginn fasse ich die historische Entwicklung der MÜ in einer Infografik zusammen. Anschließend erläutere ich den Kontext, in welchem ich die MÜ einsetzte. Leider habe ich es während dieser Zeit verpasst, jeden Fehler einzeln ausführlich zu dokumentieren. Erst spät begann ich damit, die Unzulänglichkeiten zu notieren und durch Screenshots festzuhalten. Somit baut mein Artikel auf größtenteils allgemeinen Erkenntnissen. Es folgen einige Beispiele und zum Schluss steht ein Fazit.
Historische Entwicklung der maschinellen Übersetzung: Infografik
Zum Vergrößern bitte auf die Grafik klicken. Sie öffnet sich in einem neuen Tab.
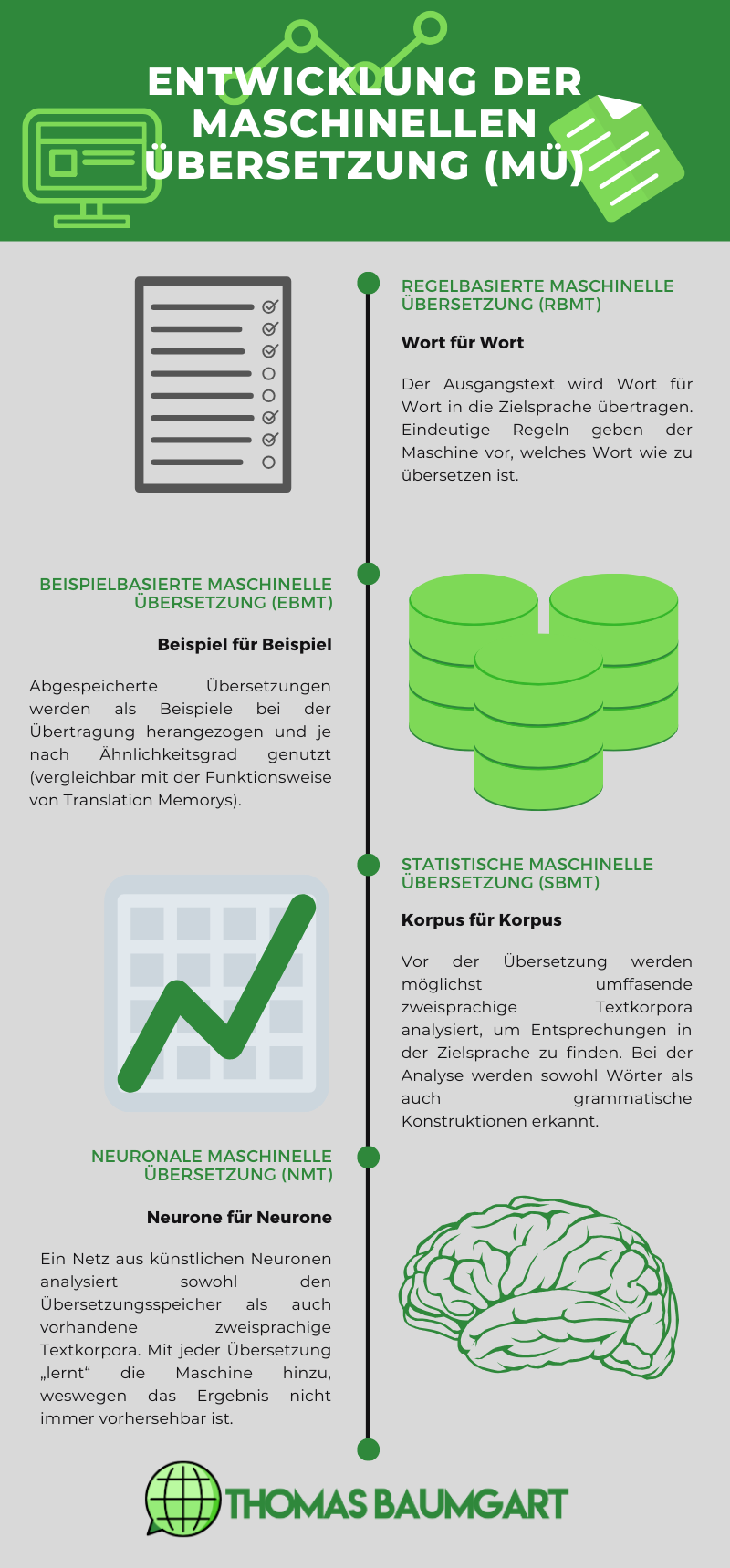
Die maschinelle Übersetzung im Einsatz
Sowohl im von uns genutzten CAT-Tool Across als auch Content-Management-System (CMS) Typo3 nutzten wir das Angebot von DeepL. Unser Team arbeitete in der Regel mit drei Texttypen, die es aus dem Deutschen zu übersetzen galt:
- Hilfe-Artikel: Diese Erklärtexte befinden sich kategorisiert im Hilfe-Center, auf welches sowohl Kunden als auch Nichtkunden Zugriff haben. Zu jedem Produkt, aber auch allgemeinen Themen (beispielsweise Datenschutz oder Verwalten des eigenen Kundenkontos), werden wichtige Informationen bereitgestellt. Die Erklärungen werden von Screenshots, Videos und Links umrahmt. Ziel dieser Artikel ist es, Anrufe beim Kundendienst zu minimieren, und sozusagen Hilfe zur Selbsthilfe zu leisten. Der Kunde hat die Möglichkeit, seine Unklarheiten oder Probleme selbst zu lösen.
- GUI-Texte: GUI steht für graphical user interface, also die grafische Benutzerschnittstelle. In meinem Fall umfasste dies alle Texte, die der Kunde nach dem Einloggen in sein Kundenkonto, Öffnen der Kunden-App und Starten der vom Unternehmen angebotenen Desktop-Softwarelösungen sieht.
- Kundenkommunikation: Alle an Bestandskunden gerichteten E-Mails und Benachrichtigungen (im Kundenkonto und als Pushnachrichten in der Kunden-App) wurden von uns aus dem Deutschen übersetzt und für das Zielpublikum angepasst. Wir informierten die Kunden beispielsweise über Vertragsbestätigungen, erfolgreich abgeschlossene Einrichtungsvorgänge oder Änderungen im Leistungsumfang der Produkte.
Allgemeine Erkenntnisse
Der Einsatz der neuronalen maschinellen Übersetzung (NMÜ) birgt einige Fehler, die nachfolgend aufgelistet werden:
- Terminologiefehler: (Fach-)Begriffe werden in der Zielsprache falsch übersetzt. Ein Beispiel: „Link“ (im Sinne von Hyperlink, Internetadresse) wird teils korrekt mit enlace, teils aber auch mit vínculo oder lazo übersetzt. Vínculo wäre noch akzeptabel, aber unüblich. Lazo ist in diesem Zusammenhang falsch.
- Terminologische Inkohärenz: (Fach-)Begriffe werden in der Zielsprache im Verlauf eines Texts oder textübergreifend unterschiedlich übersetzt, obwohl ein bestimmter Begriff durchgängig zu benutzen ist. Man spricht dann von fehlender Kohärenz. Beispielsweise erkennt DeepL Eigennamen (Produktbezeichnungen) nicht immer und übersetzt sie somit unterschiedlich.
- Inhaltliche Fehler: Inhalte werden beim Übersetzen falsch wiedergegeben. Glücklicherweise kam es bei mir, soweit ich mich entsinne, nicht zu solch gravierenden Schnitzern.
- Stilistische Fehler: Vor allen Dingen Redewendungen stellen DeepL vor große Hindernisse. Beispiel: In einer E-Mail informierten wir die Kunden darüber, dass eine PHP-Version nicht mehr unterstützt werden würde. Eine der Zwischenüberschriften im E-Mail-Text lautete „Wir lassen Sie nicht im Regen stehen!“, was DeepL erfolglos aber belustigend wortwörtlich ins Spanische übertrug …
Ebenso eine Stilfrage ist das Duzen oder Siezen des Lesers des Zieltexts. Ich arbeitete sowohl für den spanischen als auch mexikanischen Markt. Der spanische Kunde wird gesiezt, der mexikanische geduzt. Diese Unterscheidung konnte die maschinelle Übersetzung nicht bewerkstelligen. - Syntaktische Fehler: Sehr komplex strukturierte Sätze mit zahlreichen Nebensätzen werden nicht immer korrekt übertragen. Ein anderes Fehlerszenario ist, dass der spanische Zieltext zu sehr am deutschen Satzbau „klebte“. Die Information mag zwar beim spanischsprachigen Leser ankommen, jedoch würde man den Satz anders aufbauen.
- Grammatische Fehler: Da sowohl die Grammatik als auch die maschinelle Übersetzung auf logischen Regeln basiert, hat DeepL bei „berechenbaren“ grammatischen Konstruktionen selten Probleme. Auffallend ist eine grammatische Inkohärenz zwischen mehreren Sätzen. Beispiel: Am Anfang des deutschen Texts steht „Die Domain“, auf die im weiteren Verlauf mit dem Personalpronomen „sie“ Bezug genommen wird. Das Pronomen wird dann zwar korrekt mit ella übersetzt, im Spanischen ist „Domain“ jedoch männlichen Geschlechts (el dominio).
- Strukturfehler: Diese Fehler entstanden in erster Linie während der Arbeit im CAT-Tool. Verläuft ein Satz über mehrere Segmente, befindet sich also mitten im Satz ein manueller Umbruch, erkennt DeepL die Aussagen jedoch nicht als zusammenhängenden Satz, sondern übersetzt sie einzeln: Kauderwelsch vorprogrammiert.
- Zahlenfehler: Zahlen werden bei der Übersetzung inkorrekt wiedergegeben.
- Formatierungsfehler: Formatierungen (fett, kursiv, unterstrichen …) werden nicht immer korrekt übertragen. Außerdem schien DeepL beizeiten fett gedruckte Segmente innerhalb eines Satzes nicht als Bestandteil des Satzes, sondern einzeln zu übersetzen, was zu unverständlichen Ergebnissen führte.
- Interpunktionsfehler: Die Zeichensetzung des Ausgangstexts wird eins zu eins übernommen, ohne auf die Konventionen in der Zielsprache zu achten.
- BIBO (bullshit in, bullshit out): Weist der deutschsprachige Text inhaltliche, grammatische oder orthografische Fehler auf, werden diese auch in die Zielsprache übernommen. Leider habe ich mir den diesbezüglich amüsantesten Fehler nicht notiert. Ich war jedoch äußerst verwirrt, als ich im maschinell übersetzten Text auf Spanisch las, dass die Domains auf der Weide grasten, bis ich bemerkte, dass im deutschen Text nicht „verweisen“ sondern „verweiden“ stand.
Weitere Fehlerquellen und Beispiele
Links: In allen drei Textsorten, mit denen ich arbeitete, gab es zahlreiche Links. Ein Link besteht aus zwei Elementen: dem anzuzeigenden Text und der verlinkten URL. Der anzuzeigende Text mag korrekt übersetzt werden, die Link-URL muss jedoch lokalisiert werden, damit sie für den spanischsprachigen Kunden funktioniert. Einen spanischsprachigen Kunden auf eine deutschsprachige Internetseite zu verweisen, ist nicht zielführend. Hierfür braucht es einen Humanübersetzer. Die Maschine kann dies nicht leisten.
E-Mails im TXT-Format: Bei der Lokalisierung einer Kunden-E-Mail arbeiteten wir mit zwei Dateiformaten: HTML und TXT. Die HTML-Versionen werden in einem grafisch aufgearbeiteten Baukasteneditor, die TXT-Versionen in einem einfachen Texteditor (vgl. Microsoft Editor oder Notepad++) gebaut. Die TXT-E-Mails müssen bestimmte Elemente enthalten, um technisch zu funktionieren. Dazu gehören ein Header und im Anschluss folgende Zeilen, die den Absendernamen, die Absender-E-Mail-Adresse und die Betreffzeile definieren:
From: Kundendienst Test-Unternehmen <test@testunternehmen.de>
Subject: Willkommen bei Test!
Sowohl im Deutschen als auch allen anderen internationalisierten Versionen müssen diese Zeilen mit „From:“ und „Subject:“ beginnen. DeepL übersetzt jedoch eifrig und machte aus „From:“ De: und aus „Subject:“ Sujeto:. Die E-Mail-Adresse wurde jedoch nicht verändert.
De: Atención al Cliente Test <test@testunternehmen.de> Sujeto: ¡Bienvenido a Test!
In den TXT-E-Mails werden außerdem Anweisungen genutzt, die einer festen Struktur folgen, um anhand von Variablen verschiedene Informationen abzurufen und anzuzeigen. Am Zeilenanfang stehen zwei Rauten (##) und anschließend die Bedingung. Ein Beispiel: Zu Beginn der E-Mail wird anhand der Anweisungen definiert, ob der Kunde je nach Geschlecht mit „Frau“ oder „Herr“ angesprochen wird:
##if CUSTOMER.APPELATION "Frau"
Hallo Frau {VARIABLE},
##if CUSTOMER.APPELATION "Herr"
Hallo Herr {VARIABLE},
Im Spanischen wurde maschinell übersetzt daraus:
##if CUSTOMER.APPELATION "Woman"
Hola Sra. {VARIABLE},
##if CUSTOMER.APPELATION "Sir"
Hola Sr. {VARIABLE},
Hierbei treffen mehrere Fehler aufeinander. Zunächst wurde der Anweisungstext („Frau“/“Herr“) aus unerklärlichen Gründen ins Englische (!) übertragen („Woman“/“Sir“). Außerdem missachtete DeepL die unternehmensinterne Konvention, dass die spanischen Kunden mit Estimado, bzw. Estimada, angesprochen werden. Darüber hinaus endet die Anrede im Deutschen zwar mit einem Komma, im Spanischen jedoch mit einem Doppelpunkt, was DeepL ebenso nicht bemerkte.
Ein letztes Beispiel aus der TXT-E-Mail: Die deutschen Nachrichten enden stets mit den drei Segmenten
Mit freundlichen Grüßen
Ihr
Max Mustermann
DeepL übersetzte die Zeilen der Grußformel Segment für Segment:
Saludos cordiales
Tus
Max Mustermann
Aus „Mit freundlichen Grüßen“ wurde Saludos cordiales, was als korrekt übersetzt anzusehen, jedoch inkohärent ist, da die Nachrichten stets mit Atentamente, enden sollen. Im Deutschen steht nach dem Gruß kein Komma, im Spanischen jedoch schon. Dies wurde in der maschinellen Übersetzung missachtet. Interessant ist die Übersetzung von „Ihr“. Es ist verständlich, dass DeepL hier auf Probleme stieß, da es den Kontext nicht kannte und somit nicht wusste, wie „Ihr“ zu übersetzen ist. Mal bot es Tus, mal Tu, mal Su und mal Sus an. Hier kommt der Clou: Das Possessivpronomen entfällt im Spanischen. Es wird ersatzlos gestrichen:
Atentamente,
Max Mustermann
PO-Dateien: Zwei Beispiele aus der maschinellen Übersetzung von PO-Dateien. Bei PO-Dateien handelt es sich um textbasierte Portable Object-Dateien, die unter anderem zur Übersetzung von Webseiten eingesetzt werden.
<entry comment="" msgid="status-plural"><strong>Status</strong>: Aktiviert für {0} Domains</entry>wurde im Spanischen zu
<entry comment="" msgid="status-plural"><fuerte>Status</fuerte>: Habilitado para {0} dominios</entry>Die sogenannten Strong-Tags (<strong> und </strong>) heben den Text innerhalb der Tags hervor und stellt ihn fett dar. Das Element wird stets auf Englisch benutzt, DeepL erkennt dies aber nicht und übersetzt „strong“ zu „fuerte“.
Ein weiteres Beispiel:
msgid "APP.CLUSTERS.SOLUTION.REQUIRES_SPEC"
msgstr "Benötigt <span class=\"badge badge-spec\">{{spec_name}}</span>."wurde im Spanischen zu
msgid "APP.CLUSTERS.SOLUTION.REQUIRES_SPEC"
msgstr "Requiere class="badge badge-spec=">{{spec_name}}</span>."In der Zeile „msgtr“ sehen wir, dass der Aufbau des <span>-Tags in der maschinellen Übersetzung fehlerhaft wiedergegeben wurde. Somit würde die Variable {{spec_name}} nicht mehr korrekt ausgespielt werden. Die Übersetzung ist unbrauchbar.
Zum Schluss noch einige Beispiele des Einsatzes der MÜ im CAT-Tool.
DeepL hat Probleme dabei, geschützte (bzw. gesperrte) Inline-Tags zu erkennen. Im folgenden Beispiel ist der Text zwischen den eckigen Klammern eine Variable gewesen, die als Tag geschützt wurde, damit sie beim Übersetzen nicht modifiziert werden kann.
Loggen Sie sich in das [KUNDENKONTO] ein.
Im Spanischen wurde daraus:
Conéctese a esto [KUNDENKONTO].
Im folgenden Beispiel war ein Icon Bestandteil des Satzes, aber auch hier hatte DeepL Schwierigkeiten. Die maschinelle Übersetzung weist einen syntaktischen Fehler auf, da der geschützte Tag an einer inkorrekten Stelle im Satz steht.
Klicken Sie anschließend auf [Objekt [1] Bild].
wurde im Spanischen zu:
A continuación, haga clic [Objekt [1] Bild] en.
Nachfolgend noch drei Screenshots, die DeepL-Fehlinterpretationen zeigen:



Fazit
Die NMÜ, in diesem Fall repräsentiert durch DeepL, ist ein nützliches Helferlein, das uns Übersetzern durchaus unterstützend unter die Arme greifen kann. Wenn dem, was DeepL liefert, nur noch der Feinschliff gegeben werden muss, stellt der Einsatz der NMÜ eine Zeitersparnis dar, was wiederum zu einer Leistungssteigerung des Übersetzers führen kann. Wenn das Postediting jedoch zeitraubend und arbeitsintensiv ist, wäre eine vom professionellen Übersetzer selbst erstellte Übersetzung die bessere Wahl gewesen.
Sind die zu übersetzenden Segmente zu kurz, fehlt der NMÜ der Kontext, weswegen eher ins Blaue geraten und übersetzt wird. Das ist so, als ob im Wörterbuch für einen deutschen Eintrag zehn mögliche Übersetzungen im Spanischen angeboten werden und man sich willkürlich für eine Übersetzung entscheidet. Zu lange Segmente können die NMÜ ebenso überfordern, was zu inhaltlichen Verschiebungen oder gar Fehlinformationen in der Übersetzung führen kann.
Darüber hinaus kann die NMÜ insbesondere Stil- und Terminologieaspekte nicht bedienen. Allzu häufig finden sich stilistische Unebenheiten und Terminologiefehler in der maschinellen Übersetzung wieder. Wenn der Text mit Tags oder anderen Elementen gespickt ist, besteht außerdem die Gefahr, dass Strukturen, Befehle oder Variablen zerstört werden, was die Übersetzung unbrauchbar macht.
In der Kundenkommunikation per E-Mail und beim Erstellen der Oberflächentexte half uns die NMÜ nur bedingt. Hier ist der Qualitätsanspruch zu hoch, als dass die NMÜ als akzeptable Alternativlösung genutzt werden könnte. Einzig für das Hilfe-Angebot war die NMÜ eine dienliche Ergänzung. So konnten die Erklärartikel zunächst maschinell übersetzt (mit dem Hinweis zu Beginn des Texts, dass es sich um eine MÜ handelt) online gehen. Lieber der Kunde erhält zunächst eine mehr oder weniger verständliche Erklärung als gar keine. Wenn zu einem späteren Zeitpunkt genug freie Kapazitäten vorhanden waren, konnten wir die maschinell übersetzten Texte lektorieren.
Im vorigen Blog-Eintrag, der Nachlese der BDÜ-Fachkonferenz „Übersetzen und Dolmetschen 4.0“, sprach ich bereits von den Auswirkungen des Aufkommens der NMÜ. Wenn kein Qualitätsanspruch vorhanden ist, kann das Ergebnis der NMÜ zufriedenstellend sein. Wer aber sich selbst und seine internationalen Leser wertschätzt, sollte auf professionelle Übersetzer setzen.
Benötigt der Kunde ein umfassendes Highend-Gesamtpaket eines professionellen Sprachmittlers, kann die maschinelle Übersetzung uns nichts anhaben. Die Kunden, die es quick and dirty wollen, zahlten eh schon schlecht, hatten keinen Qualitätsanspruch und werden sich wohl mit den Ergebnissen der maschinellen Übersetzung zufriedengeben. Für uns Humanübersetzer bedeutet das: Klasse statt Masse. Die Maschinen werden die Übersetzer nicht ersetzen. Die Maschinen werden nur die Übersetzer ersetzen, die sich den Maschinen verschließen.
Thomas Baumgart, „Übersetzen und Dolmetschen 4.0: ‚Remove the fear factor'“ (https://thomasbaumgart.eu/blog/bduekonf19/)
Welche Erfahrungen habt ihr im Umgang mit der NMÜ gemacht? Überwiegen die positiven oder doch eher die negativen Erlebnisse? Els Peleman berichtet von Ihren Erfahrungen auf Niederländisch im Blog-Eintrag Wat kan ik wat machinevertalingen zoals DeepL niet kunnen?.
Thomas Baumgart ist Konferenzdolmetscher und Übersetzer für Spanisch, Polnisch und Deutsch. Fachgebiete sind Industrie, Technik (IT) sowie Landwirtschaft & Ernährung. Im Blog eines Brückenbauers berichtet er von seinem Berufsalltag als Übersetzer und Dolmetscher und weiteren damit verbundenen Themen.
Danke für den spannenden Bericht, der sich auch mit meinen Erfahrungen deckt.
Ich habe mit DeepL die interessante Erfahrung gemacht, dass das Programm vor alleme extreme Probleme hat, komplex gebaute Sätze aus dem Deutschen ins Englische zu übersetzen. Ich wollte einige meiner Fachtexte (Philosophie) mit DeepL aus dem Englischen ins Deutsche vor-übersetzen lassen, um sie dann zu editieren und habe es nach zwei Versuchen mit verschiedenen Texten schlicht aufgegeben. Jeder zweite bis dritte Satz war im Englischen nicht mehr verständlich, weil das Programm versucht hat, die deutsche Satzstruktur 1:1 ins Englische zu übertragen und dabei der Sinn völlig verloren gegangen ist. Die Texte direkt zu übersetzen, ging deutlich schneller. Einfache Texte waren dagegen kein Problem für DeepL.
Jetzt kommt aber der interessante Punkt: Übersetzungen derselben Fachtexte ins Französische oder Italienische (ich beherrsche Englisch, Französisch und Italienisch etwa gleich gut), die ich das Programm probehalber einmal habe durchführen lassen, sind deutlich besser gelungen. Das könnte daran liegen, dass die Syntax des Deutschen viel näher an der des Italienischen und Französischen ist als an der des Englischen. Was meinen Sie denn?
Sehr geehrter Herr Rothhaar,
haben Sie vielen Dank für Ihren Kommentar und verzeihen Sie bitte die späte Antwort. Ich finde es tatsächlich verwunderlich, dass die Übersetzungen aus dem Deutschen ins Französische/Italienische besser waren als die Übersetzungen aus dem Deutschen ins Englische. DeepL, wie auch andere Dienste für maschinelle Übersetzung, werden u. a. mit Texten „gefüttert“, damit diese dann die passenden Übersetzungen finden und erdenken. Ich hätte vermutet, dass für das Sprachenpaar Deutsch-Englisch mit Abstand die meisten Texte eingespeist wurden, weswegen die Qualität hoch sein müsste. Aber dass dem nicht so ist, zeigt Ihre Erfahrung. Ich denke, je nach Sprachenpaar und Fachgebiet sind die Übersetzungen mal besser und mal schlechter. Manche Kollegen meinen sogar, dass DeepL launisch sei und (unabhängig vom Fachgebiet) an einem Tag eine bessere und am nächsten Tag eine deutlich schlechtere Leistung erbringe. Wirklich kurios und spannend!
Liebe Grüße
Thomas Baumgart
Sehr geehrter Herr Baumgart, danke für diesen spannenden Bericht über ihre persönlichen Erfahrungen als technischer Übersetzer.
Besonders hilfreich finde ich die Erklärtexte, bei denen zu allem Produkten und allgemeinen Themen wichtige Informationen bereitgestellt werden. Gerade diese Form von Selbsthilfe findet man oft als Kunde sehr nützlich um Unklarheiten oder Probleme schnell aus der Welt zu schaffen.
Fest steht jedenfalls, dass DeepL weniger schlecht ist als andere MÜ-Systems. Danke für Ihre Mühe.